产品概述
基于开源技术的成熟大数据平台,包含以Hadoop为主的大数据生态基础引擎。平台涵盖海量数据的采集、存储、计算、分析挖掘、应用建模的需要,满足高可用性、高扩展性、高可靠性要求。终端用户可通过丰富的平台接口,完成各行业大规模数据的挖掘分析与应用对接管理。
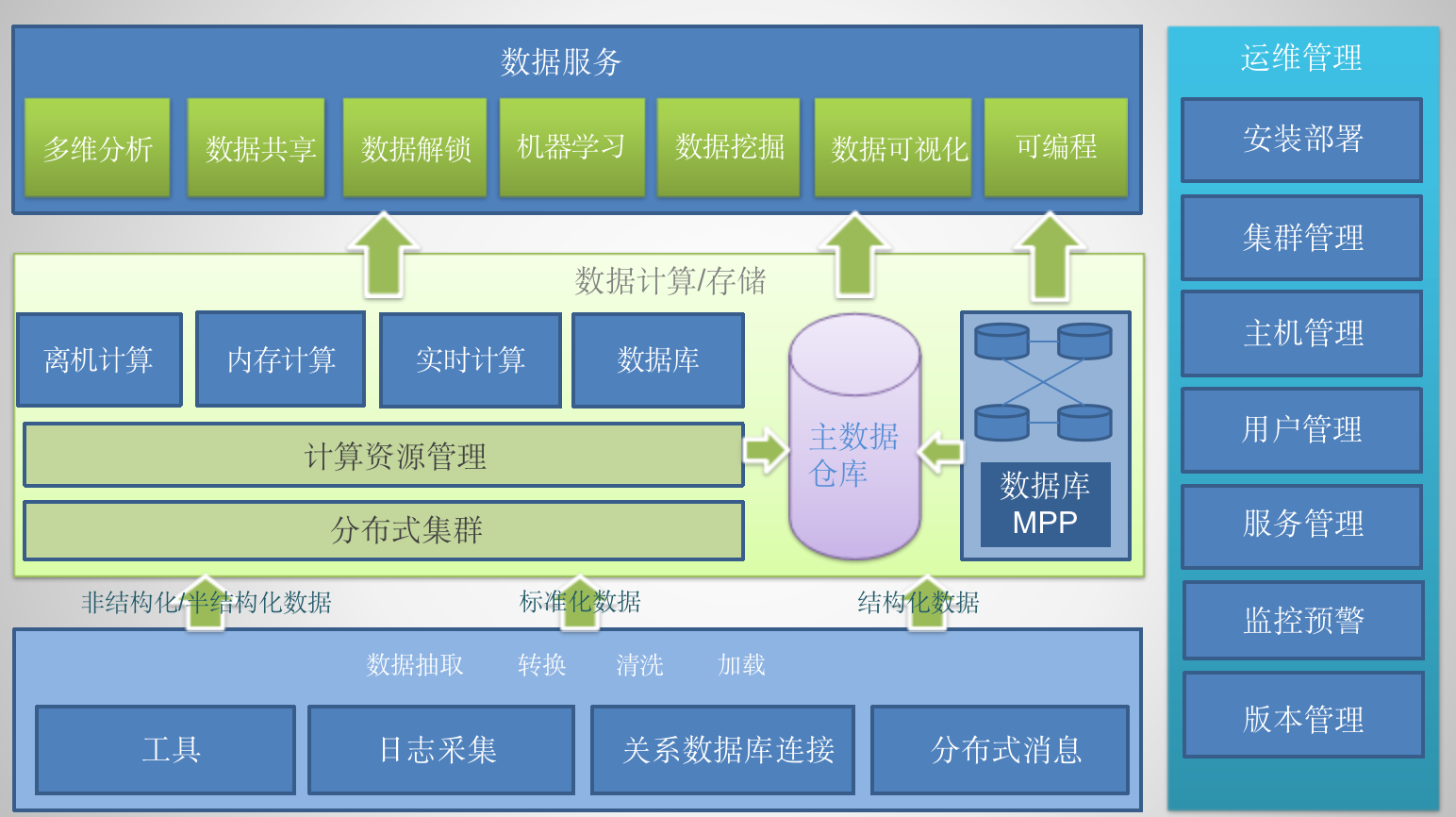
产品功能

数据采取与汇集
数据汇集支持多种格式的数据采集,并能在数据采集过程中对数据进行持续化的预处理。通过对多种采集作业提供统一的操作与管控能力,让数据的采集过程可视、可管、可控。

数据处理与计算
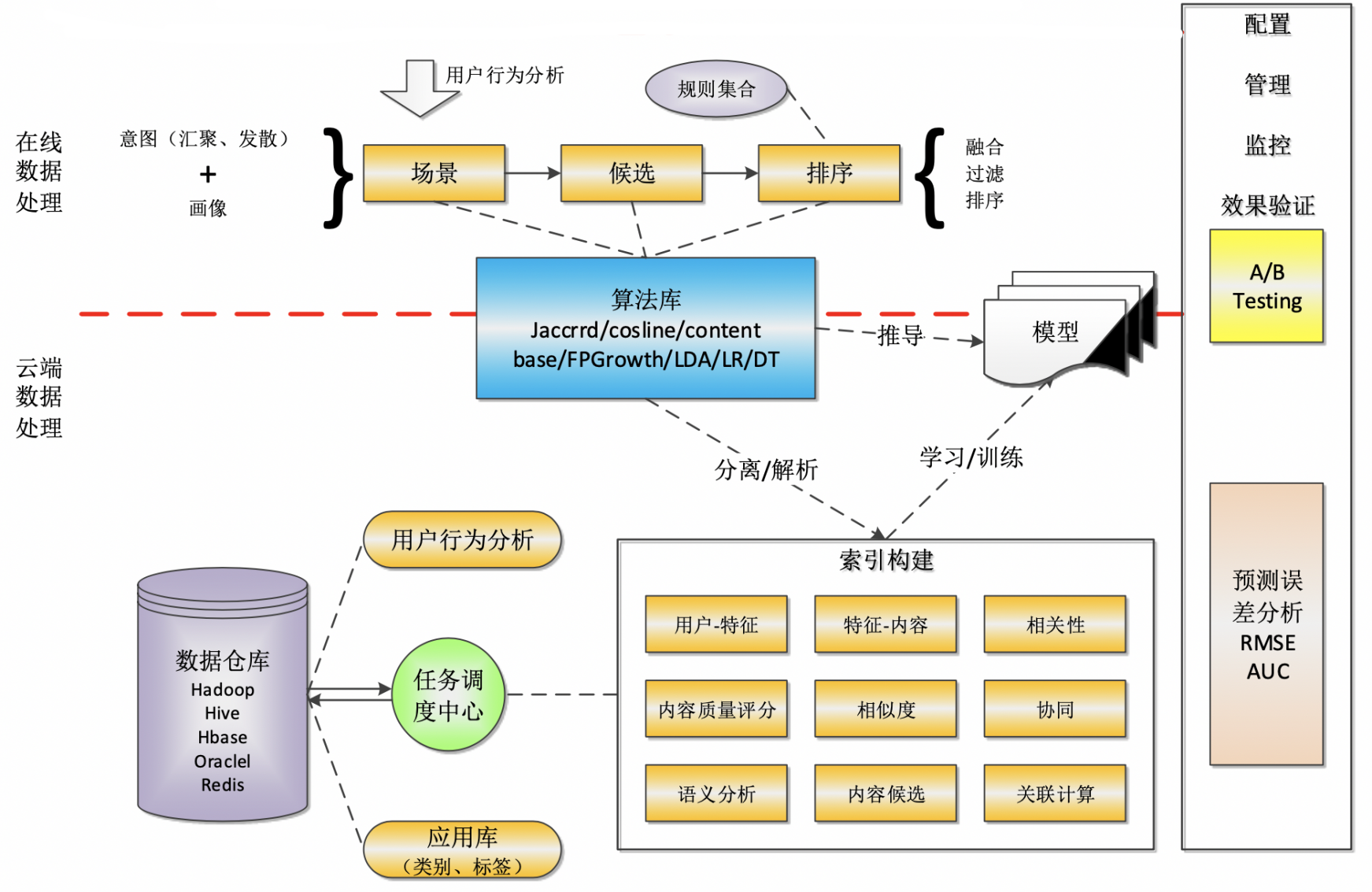
数据处理算法库提供大量的基于批处理、内存、流式计算的算法模型,这些算法模型有一些是大数据平台内置的通用性算法模型,也支持用户自定义上传算法包,数据处理算法库的主要作用是为大数据平台提供数据分析和挖掘的能力。用户根据所需选择合适的算法,或者基于自己定义的算法包,新建计算作业,由作业管理中的资源管理系统来分配和调度计算资源环境,在环境中加载算法库完成数据计算和处理。除此外,数据处理算法库还包括数据抽取算法、数据检索算法等其他计算框架的算法。

平台服务能力
大数据平台体现两种能力,即Hadoop即服务和数据即服务。
Hadoop即服务主要表现在:
以资源管理为核心,进行资源分配和调度,并根据分配的资源来承载预定的存储框架和计算框架,来体现存储框架、计算框架按需分配,按需使用,按需计量;
存储框架和计算框架可在线装卸,灵活的扩充Hadoop能力,并对外提供Hadoop组件服务。
数据即服务主要表现在:
大数据平台汇集各个数据源,并将汇集的数据对外提供服务;
大数据平台集成通用的数据模型算法,可以根据这些数据模型来进行初步的数据清洗、数据分析挖掘,并将处理后的数据开放出去,对外提供服务;
大数据平台可以插入用户自定义的数据模型,并根据用户自定义的数据模型进行分析处理,并将处理结果数据开放出去,对外提供服务。
大数据平台一方面要汇集多个数据源的数据,另一方面要将平台的数据和计算能力以标准化的API接口开放出去,应用系统可以基于这些接口来快速开发应用和支撑应用的运行。

Hadoop部署
在大数据平台服务器安装BSS-Data大数据平台套件,包括大数据管理平台、Hadoop组件等。通过Web管理界面,实现向服务器节点添加各类Hadoop服务组件,如HDFS,HBase,Solr,Spark等,提供分布式计算与存储能力;安装分布式资源管理框架YARN,实现对集群资源的管理和任务的调度监控;安装分布式海量数据采集、聚合和传输系统Flume,实现对非结构化数据的采集。大数据平台提供的组件包括:HDFS、Mapreduce、Hbase、Hive、Hue、Solr、Sqoop、Spark、Oozie、Zookeeper、Flume等,在实际使用的情况下可根据业务需要进行选择性安装。
产品功能
数据采取与汇集
数据汇集支持多种格式的数据采集,并能在数据采集过程中对数据进行持续化的预处理。通过对多种采集作业提供统一的操作与管控能力,让数据的采集过程可视、可管、可控。
数据处理与计算
数据处理算法库提供大量的基于批处理、内存、流式计算的算法模型,这些算法模型有一些是大数据平台内置的通用性算法模型,也支持用户自定义上传算法包,数据处理算法库的主要作用是为大数据平台提供数据分析和挖掘的能力。用户根据所需选择合适的算法,或者基于自己定义的算法包,新建计算作业,由作业管理中的资源管理系统来分配和调度计算资源环境,在环境中加载算法库完成数据计算和处理。除此外,数据处理算法库还包括数据抽取算法、数据检索算法等其他计算框架的算法。
平台服务能力
大数据平台体现两种能力,即Hadoop即服务和数据即服务。
Hadoop即服务主要表现在:
以资源管理为核心,进行资源分配和调度,并根据分配的资源来承载预定的存储框架和计算框架,来体现存储框架、计算框架按需分配,按需使用,按需计量;
存储框架和计算框架可在线装卸,灵活的扩充Hadoop能力,并对外提供Hadoop组件服务。
数据即服务主要表现在:
大数据平台汇集各个数据源,并将汇集的数据对外提供服务;
大数据平台集成通用的数据模型算法,可以根据这些数据模型来进行初步的数据清洗、数据分析挖掘,并将处理后的数据开放出去,对外提供服务;
大数据平台可以插入用户自定义的数据模型,并根据用户自定义的数据模型进行分析处理,并将处理结果数据开放出去,对外提供服务。
大数据平台一方面要汇集多个数据源的数据,另一方面要将平台的数据和计算能力以标准化的API接口开放出去,应用系统可以基于这些接口来快速开发应用和支撑应用的运行。
Hadoop部署
数据处理算法库提供大量的基于批处理、内存、流式计算的算法模型,这些算法模型有一些是大数据平台内置的通用性算法模型,也支持用户自定义上传算法包,数据处理算法库的主要作用是为大数据平台提供数据分析和挖掘的能力。用户根据所需选择合适的算法,或者基于自己定义的算法包,新建计算作业,由作业管理中的资源管理系统来分配和调度计算资源环境,在环境中加载算法库完成数据计算和处理。除此外,数据处理算法库还包括数据抽取算法、数据检索算法等其他计算框架的算法。
产品功能
数据采取与汇集

数据汇集支持多种格式的数据采集,并能在数据采集过程中对数据进行持续化的预处理。通过对多种采集作业提供统一的操作与管控能力,让数据的采集过程可视、可管、可控。
数据处理与计算
数据处理算法库提供大量的基于批处理、内存、流式计算的算法模型,这些算法模型有一些是大数据平台内置的通用性算法模型,也支持用户自定义上传算法包,数据处理算法库的主要作用是为大数据平台提供数据分析和挖掘的能力。用户根据所需选择合适的算法,或者基于自己定义的算法包,新建计算作业,由作业管理中的资源管理系统来分配和调度计算资源环境,在环境中加载算法库完成数据计算和处理。除此外,数据处理算法库还包括数据抽取算法、数据检索算法等其他计算框架的算法。
平台服务能力
大数据平台体现两种能力,即Hadoop即服务和数据即服务。
Hadoop即服务主要表现在:
以资源管理为核心,进行资源分配和调度,并根据分配的资源来承载预定的存储框架和计算框架,来体现存储框架、计算框架按需分配,按需使用,按需计量;
存储框架和计算框架可在线装卸,灵活的扩充Hadoop能力,并对外提供Hadoop组件服务。
数据即服务主要表现在:
大数据平台汇集各个数据源,并将汇集的数据对外提供服务;
大数据平台集成通用的数据模型算法,可以根据这些数据模型来进行初步的数据清洗、数据分析挖掘,并将处理后的数据开放出去,对外提供服务;
大数据平台可以插入用户自定义的数据模型,并根据用户自定义的数据模型进行分析处理,并将处理结果数据开放出去,对外提供服务。
大数据平台一方面要汇集多个数据源的数据,另一方面要将平台的数据和计算能力以标准化的API接口开放出去,应用系统可以基于这些接口来快速开发应用和支撑应用的运行。
Hadoop部署
数据处理算法库提供大量的基于批处理、内存、流式计算的算法模型,这些算法模型有一些是大数据平台内置的通用性算法模型,也支持用户自定义上传算法包,数据处理算法库的主要作用是为大数据平台提供数据分析和挖掘的能力。用户根据所需选择合适的算法,或者基于自己定义的算法包,新建计算作业,由作业管理中的资源管理系统来分配和调度计算资源环境,在环境中加载算法库完成数据计算和处理。除此外,数据处理算法库还包括数据抽取算法、数据检索算法等其他计算框架的算法。
产品优势
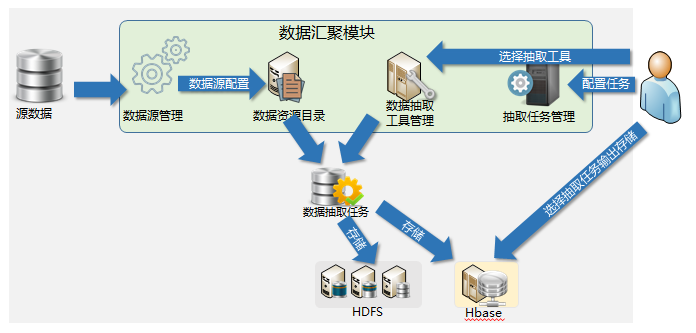
支持多种抽取工具
大数据平台支持的抽取工具包括Kettle、Sqoop、Flume、等。其中Kettle用于抽取各业务系统的结构化数据大数据数据仓库,Sqoop用于抽取结构化数据到Hadoop平台,Flume用于抽取非结构化数据到Hadoop平台。根据选择的数据源的类型,平台自动为数据源分配不同的抽取工具进行抽取,最大化对数据源的抽取效率。
定制化的数据
支持定制化的数据抽取,实现对数据源的灵活管理。在抽取之前,大数据平台支持配置抽取数据源的哪些数据,并提供资源目录展示数据源的数据结构信息以方便选择。

数据的灵活存储和使用
平台的数据抽取可根据预定的数据汇集策略,对不同数据源的数据类型进行分别汇集,分别存储,也可以根据数据量大小、运算要求通过数据直连或数据服务总线接入。对于非结构化数据、半结构化数据,平台使用HDFS进行存储;对于结构化数据,平台使用具有结构化特征的HBase进行存储。
数据汇聚流程监控
平台的统一监控体系对数据汇聚的全流程进行监控,包括数据源状态的监控、数据抽取任务的执行状态、数据抽取作业的资源占用情况、数据存储的完整性等。
支持多种抽取工具
大数据平台支持的抽取工具包括Kettle、Sqoop、Flume、等。其中Kettle用于抽取各业务系统的结构化数据大数据数据仓库,Sqoop用于抽取结构化数据到Hadoop平台,Flume用于抽取非结构化数据到Hadoop平台。根据选择的数据源的类型,平台自动为数据源分配不同的抽取工具进行抽取,最大化对数据源的抽取效率。
定制化的数据
支持定制化的数据抽取,实现对数据源的灵活管理。在抽取之前,大数据平台支持配置抽取数据源的哪些数据,并提供资源目录展示数据源的数据结构信息以方便选择。
数据的灵活存储和使用
平台的数据抽取可根据预定的数据汇集策略,对不同数据源的数据类型进行分别汇集,分别存储,也可以根据数据量大小、运算要求通过数据直连或数据服务总线接入。对于非结构化数据、半结构化数据,平台使用HDFS进行存储;对于结构化数据,平台使用具有结构化特征的HBase进行存储。
数据汇聚流程监控
平台的统一监控体系对数据汇聚的全流程进行监控,包括数据源状态的监控、数据抽取任务的执行状态、数据抽取作业的资源占用情况、数据存储的完整性等。
支持多种抽取工具
大数据平台支持的抽取工具包括Kettle、Sqoop、Flume、等。其中Kettle用于抽取各业务系统的结构化数据大数据数据仓库,Sqoop用于抽取结构化数据到Hadoop平台,Flume用于抽取非结构化数据到Hadoop平台。根据选择的数据源的类型,平台自动为数据源分配不同的抽取工具进行抽取,最大化对数据源的抽取效率。
定制化的数据
支持定制化的数据抽取,实现对数据源的灵活管理。在抽取之前,大数据平台支持配置抽取数据源的哪些数据,并提供资源目录展示数据源的数据结构信息以方便选择。
数据的灵活存储和使用
平台的数据抽取可根据预定的数据汇集策略,对不同数据源的数据类型进行分别汇集,分别存储,也可以根据数据量大小、运算要求通过数据直连或数据服务总线接入。对于非结构化数据、半结构化数据,平台使用HDFS进行存储;对于结构化数据,平台使用具有结构化特征的HBase进行存储。
数据汇聚流程监控
平台的统一监控体系对数据汇聚的全流程进行监控,包括数据源状态的监控、数据抽取任务的执行状态、数据抽取作业的资源占用情况、数据存储的完整性等。